
A Test Pyramid Heresy
The Test Pyramid is a staple in Test Automation theory, and is used by many teams as the basis of their test automation strategy. But does it still work for modern development practices? Are there better and more efficient ways of thinking about test automation today?
One of the more well-known models in the Test Automation world is the Test Pyramid. Originally coined by Mike Cohn in 2009, the Test Pyramid is designed to show what a well-structured test suite looks like, based on the application layers being tested. It has gone through many variations over the years, but generally it looks something like this:
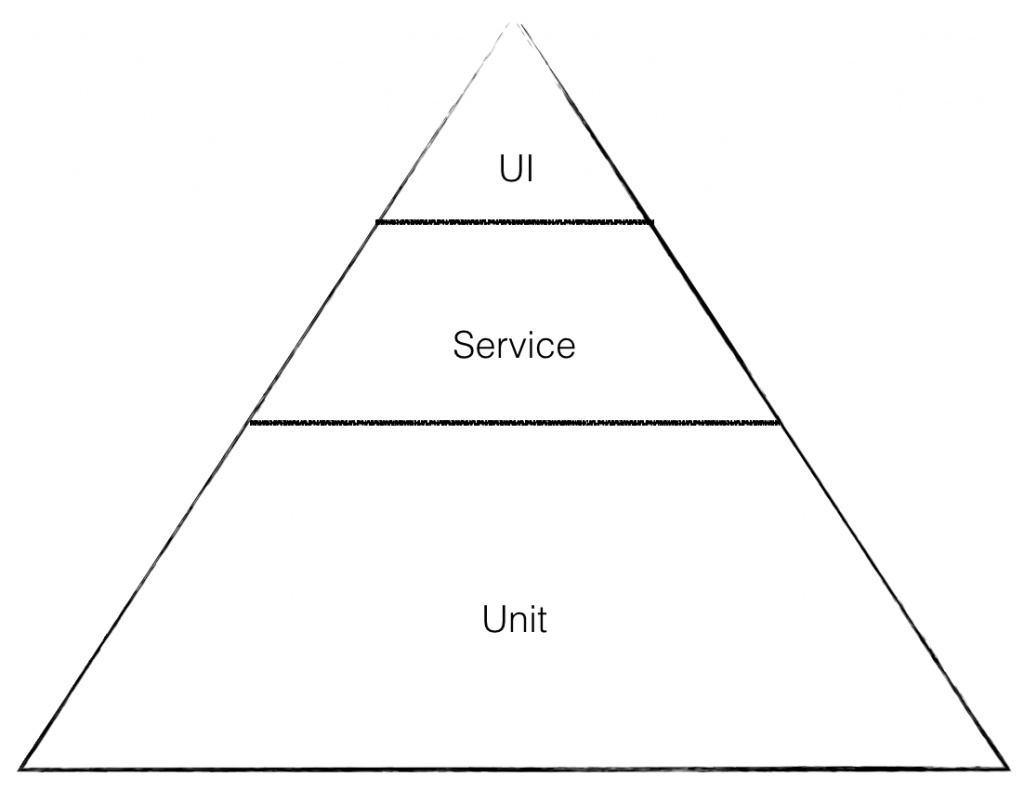
The basic idea is simple: end-to-end User Interface (UI) tests (the ones at the top) tend to be slow to run and expensive to write and maintain. Smaller, faster running unit tests give much faster feedback, making bug fixes quicker and less expensive. In between, service level tests verify how components interact and help test the application logic independently of the user interface. If your test suite contains mostly fast running unit tests, it will give you much faster feedback than one dominated by UI tests.
The opposite scenario (which Alister Scott refers to as the software testing ice-cream cone) describes a situation where the team relies on automated web tests to do most of the testing. This makes the test suite run more slowly (often much more slowly), which makes it slower and more expensive to release new features and to react to evolving requirements.
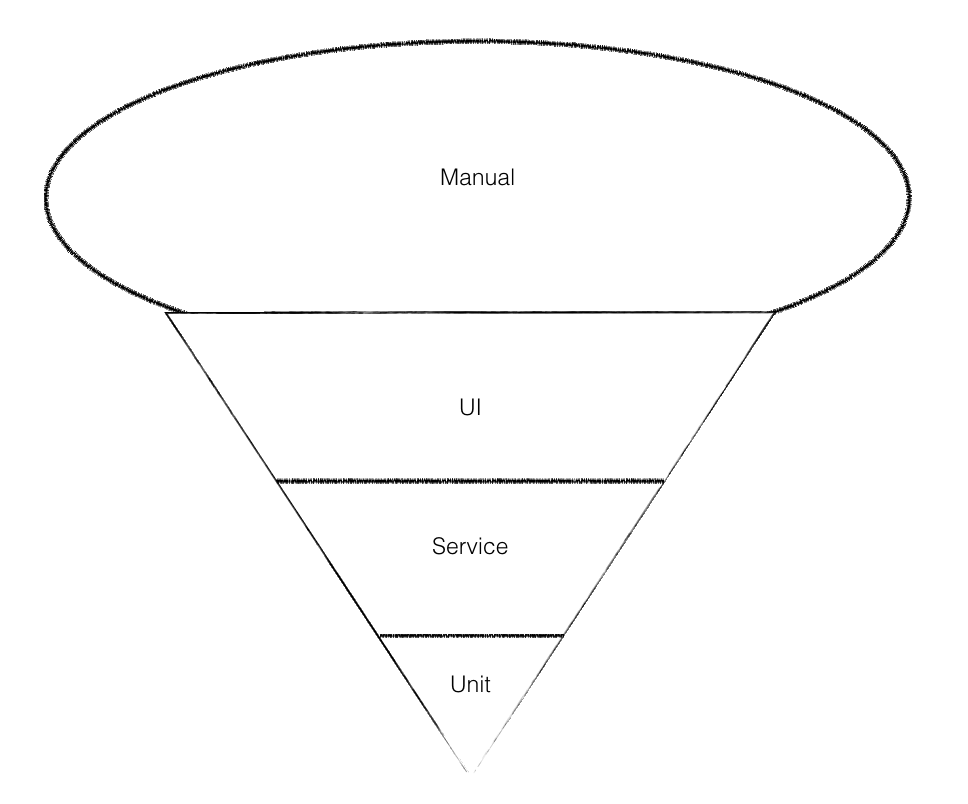
An over-reliance on UI-based end-to-end tests is certainly an anti-pattern, and causes many problems beyond test execution speed. Too many UI-based tests, often perceived as the domain of the "QA folk", can lead to developers taking less ownership of the quality of their own code, relying on the automated web tests to catch any bugs they might introduce. It can also perpetuate a culture where automated tests are used purely as "regression" tests, and implemented well after work on a feature has been completed and delivered, which greatly reduces the value of the tests as a feedback mechanism.
So the Test Pyramid makes a valid point: Don't use a web test where a service or unit test could do the same job.
But does the Test Pyramid apply in all projects, or for all teams? Do all effective automated test suites follow the distribution described in the pyramid? Is it really the best way to approach testing on your project?
The short answer is no.
Does the pyramid still stand?
All models are wrong; some models are useful - George Box
The Test Pyramid is a model, and like all models, it is wrong, though it is occasionally useful.
Technology, development practices and toolsets have all evolved a lot since the mid 2000s, and there are many cases in projects today where the Test Pyramid would be misleading. Microservices and serverless computing platforms such as AWS Lambdas have very different testing requirements to a fully-fledged web application. Modern JavaScript frameworks such as AngularJS and React, and tools like Protractor and PhantomJS, make it easy and fast(er) to unit test complex user interfaces. And many mobile applications have a rich user experience that cannot be tested through the service layer.
In many of these cases, a rigid interpretation of the Test Automation model can lead to inappropriate or ineffective test automation strategies, with too few, or too many, tests at different levels.
The problem with the test pyramid model is that it focuses on the wrong thing. It reasons in terms of how tests are implemented, rather than what features the tests are testing, or why we are writing the tests in the first place. But rather than thinking in terms of what layer is being tested, or how a test is written, it is far more useful to think in terms of how a test adds value by increasing confidence or reducing risk.
Tests add value in different ways, depending on where they come from (their source, or provenance), and on what purpose they serve (their role).
Different tests come from different sources
Different tests come from different sources, and this influences how you automate them. With a slight over-simplification, we can group tests by provenance into three broad categories:
- Business tests
- QA tests
- Developer tests
Business tests
For teams practicing Behaviour Driven Development, for example, acceptance criteria come from conversations with the business or with business analysts. These acceptance criteria describe what the application is supposed to do, and how it does so, in high level business terms. When we automate the acceptance criteria (and they become high level executable specifications), we speed up the feedback cycle and reduce risk significantly, which benefits the team as a whole. Automated acceptance criteria are an essential part of modern software development.
QA tests
Testers help discover and clarify the acceptance criteria, but they also identify other scenarios beyond those covered by the acceptance criteria. For example, testers might want to ensure that business rules are respected, or calculations are correct, for a large number of different scenarios. Or they may want tests to check that an application can support the required number of users or transactions. These more detail-focused tests demonstrate that an application is fit for purpose.
Developer tests
Developers also contribute to the test base, especially if they are practicing Test Driven Development. Developers are likely to value tests that build confidence in the code base. They also benefit from tests that illustrate how components are intended to work, making it easier to understand and safer to make changes without introducing new bugs.
These distinctions might sound a little like the three levels of the Test Pyramid, with the business-focused scenarios implemented by UI tests, and the more technical scenarios implemented via service and unit tests. But this is misleading. The provenance of a test actually has little bearing on how it is implemented. For example, only a small part of the business focused acceptance tests would be implemented as end-to-end UI tests (the ones that illustrate typical user journeys through the system).
Different tests play different roles
Different tests also play different roles in a project. The traditional role of automated tests is to check that an application behaves correctly; in other words, to demonstrate that the application works. However, Behaviour Driven Development practices show how tests can also play a role as "living documentation", to describe and illustrate business rules. We can even use tests, or more precisely, concrete examples that may eventually become tests, to learn more about the features we need to implement.
We can think of tests as falling into three broad categories:
- Some tests help us Discover
- Some tests Describe
- And some tests Demonstrate
Different practices and tools work best for each activity and at each level of detail:
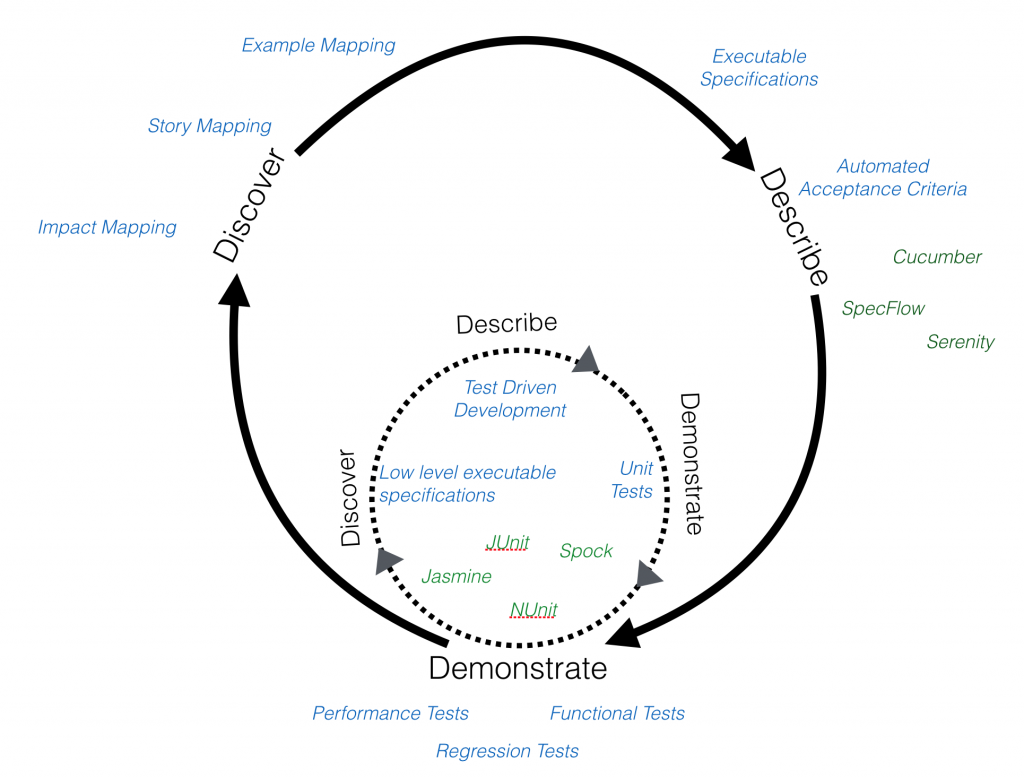
Let's look at each of these categories more closely.
Tests that Discover
Testing activity should start well before any test automation happens. Good acceptance criteria, the building blocks of automated acceptance tests, illustrate concrete examples of how a user interacts with an application to achieve a business goal. But before you can nail down these acceptance criteria, it helps to use conversations around examples to explore the problem domain and build up your understanding. This is the basis of Behaviour Driven Development. The examples are conversation-drivers: you don't need to automate all of them, though many will likely find their way into the automated acceptance criteria of the Describe category below.
At a lower level, you can use examples and tests to discover an optimal API design, essentially by writing the code you would like to have in the form of tests. The idea of crafting a well-designed API through tests is at the heart of Test-Driven Development.
Once you have found an API design you are happy with, you can refactor and expand your tests in the form of low level executable specifications that would fall into the Describe category.
Tests that Describe
Some tests describe. Their goal is to explain a business rule or a feature, in high-level terms.
Well-written acceptance tests are a great example of tests that describe. High level executable specifications come directly or indirectly from the business, and work well when they are expressed using a language and domain vocabulary that the business can understand. For this reason, many teams use BDD tools such as Cucumber or SpecFlow to write acceptance tests in the form of executable specifications, like the following:
Scenario Outline: The maximum credit card limit depends on the customer's salary
A customer needs a salary of at least £10,000.
There are two types of card, one with a limit of £2500,
and another with a limit of £5000
Given an individual customer with an annual salary of <Salary>
When the customer applies for a credit card
Then the credit card application should be <Approved or Refused>
And if approved, the maximum credit limit should be <Max Limit>
Examples: Credit card approval for different salary levels
| Salary | Approved or Refused | Max Limit | Notes |
| £5000 | Refused | 0 | Must be over £10,000 |
| £15,000 | Approved | £2500 | Up to £15,000 |
| £25,000 | Approved | £5000 | Over £15,000 |
| £100,000 | Approved | £5000 | £5000 is the max limit|
These executable specifications might describe business rules (like the example above), and could be automated using non-UI tests. Others might be more focused on user interactions, like the following:
Feature: Adding new items to the list of things to remember
In order to avoid having to remember things that need doing
As a forgetful person
I want to be able to record what I need to do in a place where I won't forget about them
Scenario: Adding an item to an empty list
Given that James has an empty todo list
When he adds 'Buy some milk' to his list
Then 'Buy some milk' should be recorded in his list
Scenario: Adding an item to a list with other items
Given that Jane has a todo list containing Buy some milk, Walk the dog
When she adds 'Buy some cereal' to her list
Then her todo list should contain Buy some milk, Walk the dog, Buy some cereal
We can also use tests to describe and document our APIs and classes. The target audience will be developers, rather than testers and BAs, so the executable specification will be a little more technical, but readability is still key. The following code sample illustrates how a low-level component can be documented using Spock, a Groovy-based BDD unit testing tool:
class WhenDisplayingTagNamesInAReadableForm extends Specification {
def inflection = Inflector.instance
def "tag names expressed as singular nouns can be displayed in plural form"() {
when: "I find the plural form of a single word"
def pluralForm = inflection.of(singleForm).inPluralForm().toString();
then: "the plural form should be grammatically correct"
pluralForm == expectedPluralForm
where:
singleForm | expectedPluralForm
'epic' | 'epics'
'feature' | 'features'
'story' | 'stories'
'stories' | 'stories'
'octopus' | 'octopi'
'sheep' | 'sheep'
'fish' | 'fish'
'dynamo' | 'dynamos'
'hippopotamus' | 'hippopotamus'
'parenthesis' | 'parentheses'
'' | ''
}
...
}
In all of these cases, the role of these tests is do describe and illustrate how the system works, and the way we implement them varies depending on their provenance and target audience.
Tests that Demonstrate
Sometimes describing a feature with a nice set of executable specifications is all you need. The acceptance criteria are comprehensive enough, and the scope of the feature limited enough, to give us confidence that the feature is fit for purpose.
For small, focused features such as Micro Services or Lambdas, this may well be the case, and we can stop there.
But most often, we need to demonstrate that the feature works in more detail. We might need to check boundary conditions, edge cases or error handling. We might need to write comprehensive data-driven tests for a complex pricing algorithm. We might need to check that the full range of error codes returned from a mainframe service are processed correctly. And so on.
The amount demonstrating we need to do largely depends on the complexity of the feature we are implementing. When implementing a feature requires a bit more work, or involves several classes or components, we drill down into the details and repeat the Discover/Describe/Demonstrate cycle at the next level down, until all of the top level acceptance criteria pass and we are confident in the code base.
An Automated Testing Quadrant
Automated tests that emerge from the Discover and Describeactivities tend to be broader in scope, focusing on business goals, business rules, and how a user interacts with the application to achieve these goals. They can lack on detail, since their aim is to illustrate key examples of how the system works. Automated tests that demonstrate tend to be more detail-focused and comprehensive.
If we combine this with the Provenance of the examples that we discussed earlier, we get a distribution like the one shown here:
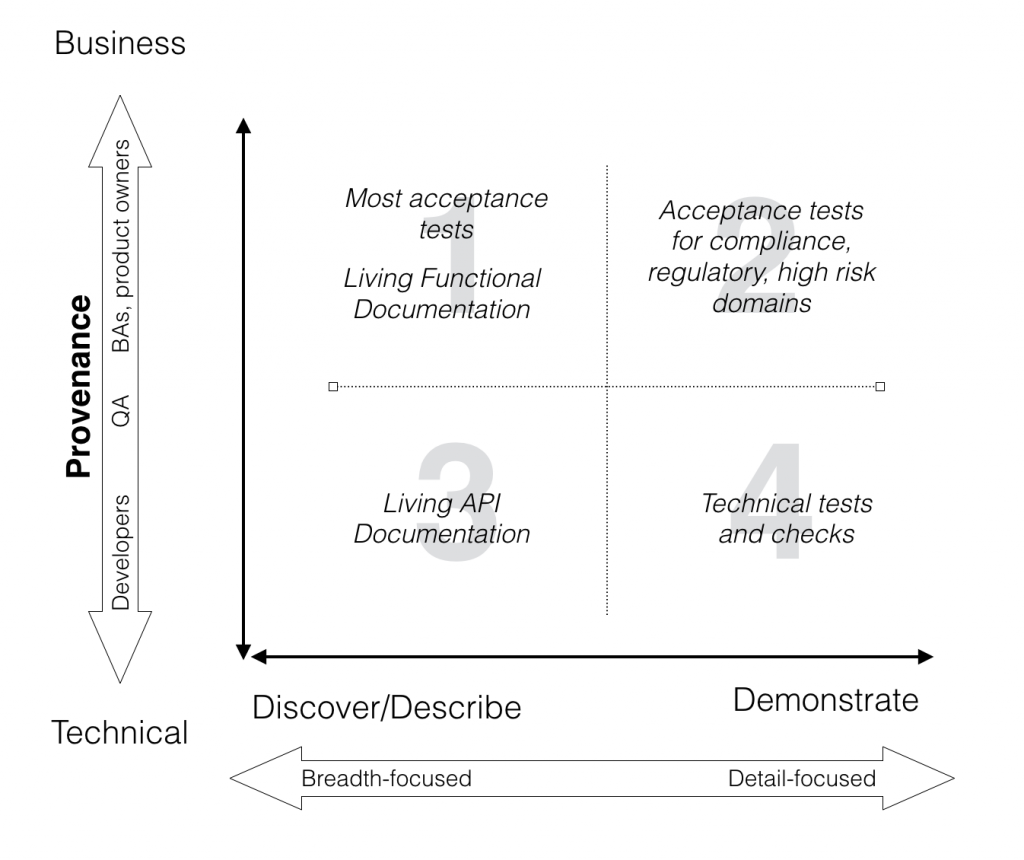
These quadrants help us understand the role and nature of the different types of tests in our projects:
- Quadrant 1 tests focus on high level business outcomes and flows, and come directly or indirectly from the business. They use key examples of what the system does and how it works to give an overall understanding.
- Quadrant 2 tests are still very business focused, but are more detailed and comprehensive. Business analysts and testers are key players in this quadrant.
- Quadrant 3 tests are written by and for developers, with the aim of making future maintenance easier and cheaper.
- Quadrant 4 tests are the technical equivalent of Quadrant 2 tests, and aim to ensure that technical components are fit for purpose. The boundary between tests that illustrate how to use an API and tests that demonstrate edge conditions and so on is more blurred for a technical audience.
Test distribution varies from project to project. For example, while Quadrant 1 tests are applicable for virtually any project, an application in Finance or Insurance is likely to have many more Quadrant 2 tests than an Ecommerce one. A small Microservice or Amazon Lambda might have a majority of tests in Quadrant 3, whereas a monolithic architecture may need many Quadrant 4 tests as well.
Goldilocks Test Suites
One of the nice things about using an outside-in approach like the one described here is that it encourages you to write just enoughtests to give you confidence in your code; not too few, but also not too many. Too few tests reduces your confidence in your application, leading to more manual testing and slower deployment cycles. But automated tests, like anything else, have a diminishing return on investment, and it is possible to have too many tests, tests that take time to write, increase maintenance costs, and slow down the build.
An outside-in approach also helps you think less in terms of the layers of the test pyramid, and more in terms of writing tests that get the job at hand done. Be pragmatic: write the simplest and fastest test that you can get away with that does two things:
- Illustrates the point you are trying to demonstrate
- Make it easy to identify the cause of the problem should the test fail
For example, if you are illustrating how a user achieves a goal via a web application, and end-to-end UI test will probably be most appropriate. If you are illustrating a localised UI feature, the test will most likely be a web test, though if your UI is implemented in AngularJS it might use Protractor and PhantomJS. And if you are illustrating a business rule or calculation, a unit or service-level test will most likely be sufficient.
Conclusion - step away from the pyramid
The Test Pyramid is a useful model. It highlights the risks of writing too many long-running, end-to-end UI tests and too few unit tests. But it should not be treated as a one-size-fits-all model, and less still as test automation dogma.
A good test automation strategy should focus on writing the most appropriate tests for your project, based on the value they add, not on the layers they test or the way the tests are implemented. A BDD-style outside-in approach like the one described in this article gives you effective feedback and high meaningful test coverage, with just the right amount of tests to get the confidence you need, but no more. So step away from the pyramid and adopt a more flexible strategy suited to the needs of your project.
